Le but de cet article est de permettre à des développeurs/utilisateurs Qlik Sense disposant de droits d’accès standard (pas d’API Rest) de construire rapidement un data catalogue fonctionnel couvrant leur périmètre (i.e. tous les QVD auxquels ils ont accès).
Cet article ne prétend pas à une quelconque exhaustivité, il s’agit au contraire d’une heuristique. Il serait possible d’enrichir ce data catalogue avec des données applicatives, ou de suivre une autre approche demandant des droits plus étendus, de type administrateur.
Cet article est pour vous si :
N.B. :
L’idée derrière cet article m’a été inspirée d’un post de lien Steve Dark sur la Qlik Community, ma contribution principale a été de systématiser sa démarche via une exploration récursive.
Chaque fichier QVD contient un en-tête XML contenant nombre d’informations utiles, et souvent méconnues, on peut y trouver, entre autres :
Plus précisément, ces informations sont répartis dans deux en-têtes distincts, le premier contenant les informations du QVD en lui-même (QvdTableHeader), le second des détails pour chaque champ (QvdFieldHeader).
N.B. :
Interroger les en-têtes d’un QVD est infiniment plus rapide que de lire (même partiellement) le contenu du QVD lui-même. A titre informatif, j’ai pu scanner 5000 QVD en quelques minutes.🚀
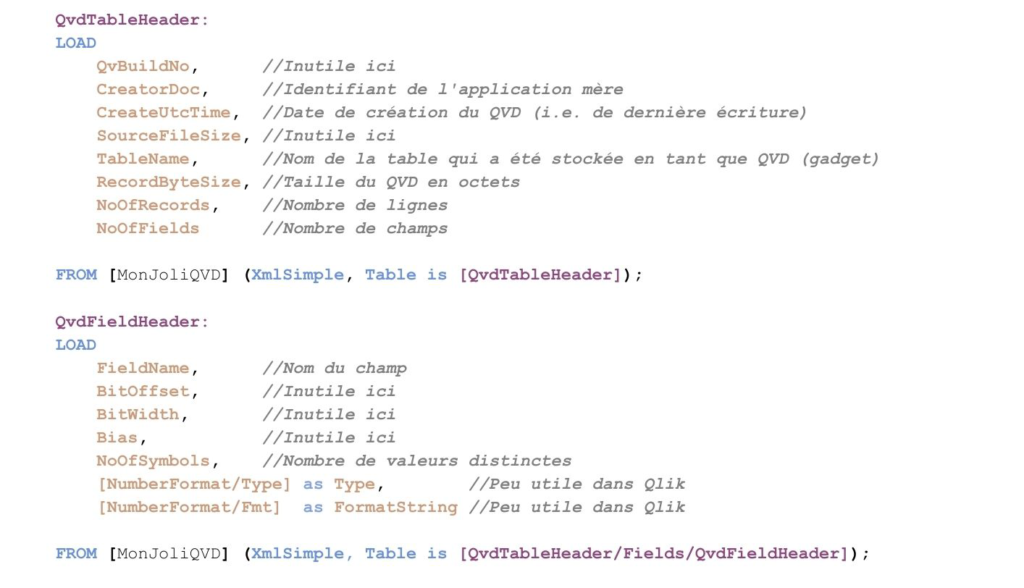
Vous remarquerez que ces deux tables ne sont pas naturellement liées entre elles, ce sera donc à nous de faire la réconciliation.
Pour ce faire, vous verrez dans la suite que j’utilise une clé QVDKey concaténant le nom du QVD et son timestamp (= date de création/rafraîchissement). Tant que personne ne créé pas simultanément deux QVD avec le même nom la même seconde, nous sommes tranquilles, cette clé sera unique.
Explications :
Maintenant que nous savons récupérer les métadonnées d’un QVD, il est logique de vouloir systématiser le processus, et donc de faire une boucle géante sur tous les QVD que l’on a en magasin : allons-y !
Hélas, la réalité vient s’interposer : ce n’est pas possible, en tout cas pas sans être administrateur… Il va donc nous falloir ruser, et opter pour une approche semi-automatique.
Le principe va être de lister toutes nos data connexions (donc tous nos répertoires contenant des QVD), et pour chacune d’entre elles, scanner récursivement son contenu. Cela peut sembler complexe, mais avec la fonction “sub”, le code reste relativement simple.
Attention, si vous avez des data connexions “redondantes”, i.e. une data connexion mère et des data connexions filles, pensez à prendre la connexion parente.
D’ailleurs, petite astuce :💡👉 une fois que vous aurez fait briller les yeux des responsables Qlik avec votre data catalogue, proposez-leur de créer une dataconnexion à la racine des dossiers où sont stockés les QVD, s’ils acceptent, vous pourrez scanner tout le serveur en une fois )
Trêve de bavardages, vous trouverez ici la version complète du scan récursif telle que je l’utilise. Vous remarquerez qu’en plus des métadonnées strictement présentes dans les en-têtes XML, j’utilise des fonctions plus classiques pour récupérer le timestamp des QVD, leur data connexion, etc… Tant qu’à faire.
Script à réutiliser :
Ces 3 blocs de codes peuvent être placés dans 3 sections différentes, la seule partie à modifier est indiquée en rouge, elle correspond à la liste des data connexions que vous souhaitez scanner.

Modèle de données :
Une fois le script précédent exécuté, vous vous retrouverez avec ce modèle de données, qui a le mérite de la simplicité :

👉 Vous remarquerez que le champ “Mother app ID” peut servir de clé pour ramener des données applicatives, si vous en avez (stream, responsable, taille, dernière modification par, etc…)
Architecture applicative :
La légèreté de l’algorithme récursif permet son exécution quotidienne, même sur de grands volumes de données. Personnellement, je l’exécute chaque soir à 23h30, dans une application que j’appelle “Data Catalogue Back-end”. En fin d’exécution, elle stocke les résultats du scan dans deux QVD.
Ensuite, une seconde application, le “Data Catalogue” peut elle lire ses QVD, éventuellement les enrichir, et proposer des visualisations à vos utilisateurs :
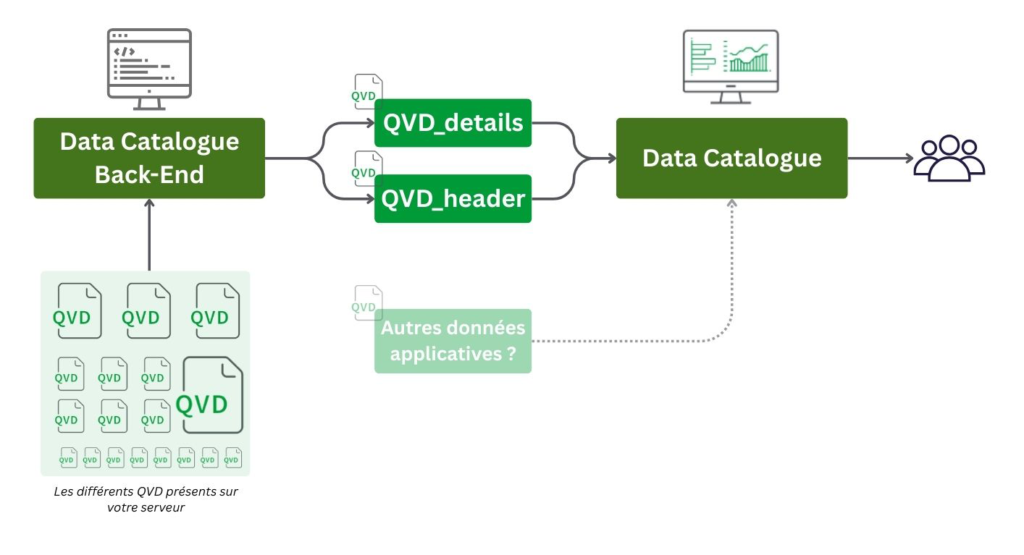
Les visualisations suivantes sont issues d’une application de data catalogue réalisée pour un client. Par rapport au modèle vu précédemment, il comporte en plus :
4.1. Overview – pour des responsables infra
Cette page présente une vue générale, principalement à destination d’architectes ou de responsables, souhaitant visualiser d’un coup d’œil l’ensemble des QVD dont iels ont la gouvernance.
Description du graphique à bulle :
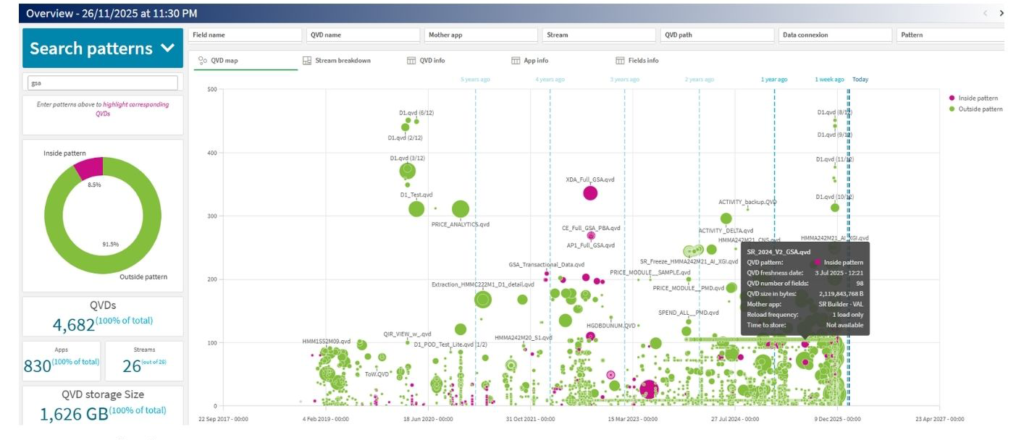
Interprétations :
Une autre page de la même application, davantage destinée à un public de développeurs ou d’utilisateurs métiers avertis, souhaitant par exemple chercher des données ou contrôler la fraîcheur d’un QVD.
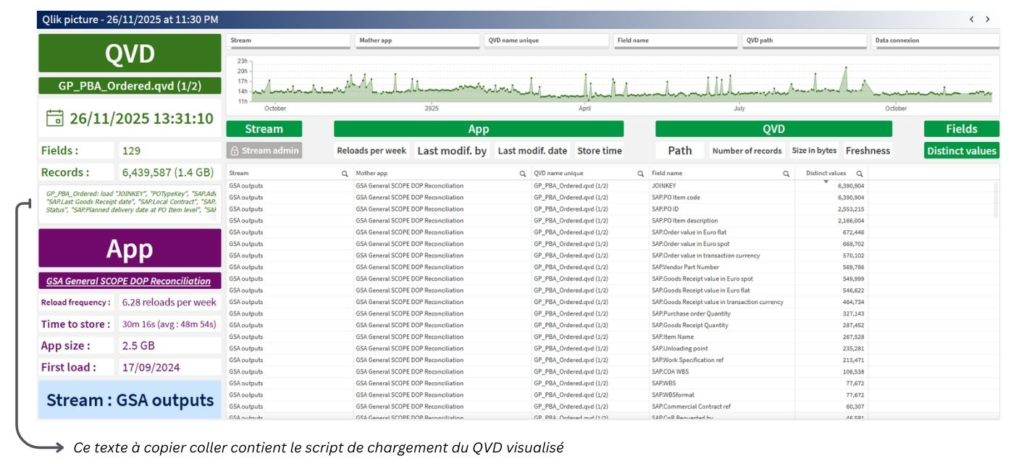
Cas d’usage :
Supposons que nous sommes contacté par une personne du métier, qui souhaite des informations sur les demandes d’achat (Purchase Order ou PO, dans la langue de Shakespeare).
Même sans rien connaître aux PO, nous pouvons aller dans le data catalogue, y rechercher les mots “demande d’achat”, “DA”, “Purchase Order” et “PO”.
Mettons que nous trouvons alors sept QVD dans lesquels ces mots apparaissent. Nous pouvons ensuite chercher ceux qui sont mis à jour de manière régulière.
Admettons qu’il reste deux QVD en compétition. Il pourra alors être intéressant de regarder lequel des deux contient le plus de PO, donc de valeurs distinctes.
Une fois que nous avons trouvé ce qui semble être le QVD de nos rêves, nous pouvons par exemple contacter la personne responsable du stream de l’application mettant à jour ce QVD, pour lui demander des informations complémentaires.
Dans l’intervalle, vous pouvez copier/coller (comme vu plus haut) dans une nouvelle application le code permettant de charger le QVD, par exemple pour l’exporter à votre utilisateur métier, qui est par définition pressé… ⏱️
=> Sans connaissance métier ni renseignements préalables, nous avons réussi à trouver un QVD à jour, bien rempli et (on l’espère !) pertinent pour un métier.
Tags :
Il est possible d’attacher à un QVD un ou plusieurs tags personnalisés, comme expliqué en détails ici. On peut se les représenter comme des variables attachées aux QVD.
Personnellement, je les utilise pour sauvegarder dans chacun de mes QVD le temps qu’il a fallu pour les générer, par exemple :

Historisation :
Dans certains cas, historiser tout ou partie des données obtenues via notre scan peut s’avérer intéressant. Notamment pour monitorer l’évolution :
Comme cela complexifie le code, je ne l’ai volontairement pas abordé ici, de nombreux articles concernant l’historisation de données sur Qlik existent déjà.
Traçabilité descendante (forward data lineage) :
Savoir quels sont les QVD consommés par une application est un sujet malheureusement plus complexe à automatiser, et suppose des droits de type administrateur (que je viens d’acquérir, peut-être le sujet d’un futur article…)
Si vraiment vous êtes désespérés, il est toujours manuellement possible d’ouvrir une application pour voir d’où viennent ses données. C’est (très) fastidieux, mais néanmoins toujours faisable.
Ayant été désespéré moi-même, j’ai essayé de creuser le sujet via une approche semi-automatique, en créant un parseur capable d’analyser le script d’une application pour reconnaître les instructions store, mais… j’ai échoué : QVD chargés dans des boucles, chemins d’accès variabilisés, store conditionnels… Prévoir tous les cas de figures est un petit cauchemar, et vous ne voulez pas utiliser un data lineage qui fonctionne 85% du temps.
N.B. : parser les logs de chargement devrait être infiniment plus simple que le script (tout y est explicité), mais encore une fois, il vous faut des droits administrateurs…
Thomas Delesalle
Disclaimer : Malgré la présence de nombreuses frimousses (french for emoji 🥖), cet article a été écrit sans le recours à une intelligence artificielle.